
操作字段解析顺序
Multiple Query Execution 提供的 @export 指令的目标是将字段(或字段集合)的值导出到变量中,以便在 Query 的其他地方使用。
如果在将值导出到变量之前就读取了该变量,则此指令将无法正常工作。因此,引擎需要提供一种控制字段执行顺序的方法。
Gato GraphQL 提供了一种通过 Query 本身来操作字段执行顺序的方法。引擎按类型逐步迭代加载数据,首先解析 Query 中遇到的第一个类型的所有字段,然后解析第二个类型的所有字段,依此类推,直到没有更多类型需要处理为止。
例如,以下涉及 Director、Film 和 Actor 类型对象的 Query:
{
directors {
name
films {
title
actors {
name
}
}
}
}...由 GraphQL 引擎按以下顺序解析:

如果已处理的类型在 Query 中再次被引用以获取未加载的数据(例如:来自额外对象,或已加载对象的额外字段),则该类型将被再次添加到迭代列表的末尾。
例如,如果还 Query Actor 的 preferredDirector 字段(返回 Director 类型的对象),如下所示:
{
directors {
name
films {
title
actors {
name
preferredDirector {
name
}
}
}
}
}...则 GraphQL 引擎按以下顺序处理 Query:

让我们看看在单个 Query 中执行 @export 时的情况。第一次尝试时,我们按照通常的方式创建 Query,不考虑字段的执行顺序:
query GetPostsAuthorNames {
user(by: { id: 1 }) {
name @export(as: "authorName")
}
posts(filter: { search: $authorName }) {
id
title
}
}运行 Query 时,会产生以下响应:
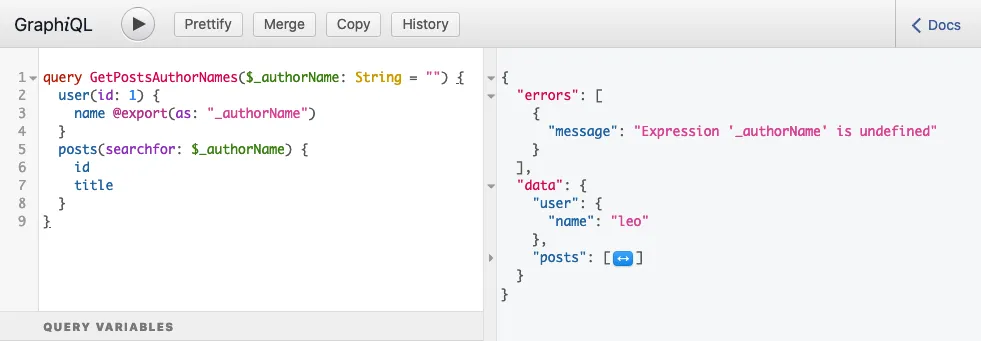
...其中包含以下错误:
{
"errors": [
{
"message": "Expression 'authorName' is undefined",
}
]
}此错误意味着,在读取变量 $authorName 时,它尚未被设置,处于 undefined 状态。
让我们看看为什么会发生这种情况。首先,我们分析 Query 中出现的类型,以注释形式标注如下:
# Type: Root
query GetPostsAuthorNames {
# Type: User
user(by: {id: 1}) {
# Type: String
name @export(as: "authorName")
}
# Type: Post
posts(filter: { search: $authorName }) {
# Type: ID
id
# Type: String
title
}
}为了处理类型并加载数据,数据加载引擎将 Query 类型 Root 添加到 FIFO(先进先出)列表中,从而使 [Root] 成为传递给算法的初始列表,然后按顺序迭代这些类型:
| # | 操作 | 列表 |
|---|---|---|
| 0 | 准备 FIFO 列表 | [Root] |
| 1a | 弹出列表中的第一个类型(Root) | [] |
| 1b | 处理从 Root 类型 Query 的所有字段:→ user(by: {id: 1})→ posts(filter: { search: $authorName })将它们的类型( User 和 Post)添加到列表 | [User, Post] |
| 2a | 弹出列表中的第一个类型(User) | [Post] |
| 2b | 处理从 User 类型 Query 的字段:→ name @export(as: "authorName")由于它是标量类型( String),无需添加到列表 | [Post] |
| 3a | 弹出列表中的第一个类型(Post) | [] |
| 3b | 处理从 Post 类型 Query 的所有字段:→ id→ title由于它们是标量类型( ID 和 String),无需添加到列表 | [] |
| 4 | 列表为空,迭代结束。 |
这里可以看到问题所在:@export 在步骤 2b 执行,但变量在步骤 1b 就已被读取。
这正是我们需要控制字段执行流程的地方。实现的解决方案是延迟读取已导出变量的时机,通过人为地从 Root 类型 Query self 字段来实现。
self 字段,顾名思义,返回同一个对象;应用于 Root 对象时,它返回同一个 Root 对象。你可能会想:"如果我已经有了根对象,为什么还要再次获取它呢?"。因为这样引擎的算法就需要将这个新的 Root 引用添加到 FIFO 列表的末尾,我们可以有意地在每次迭代之前或之后分配所 Query 的字段。
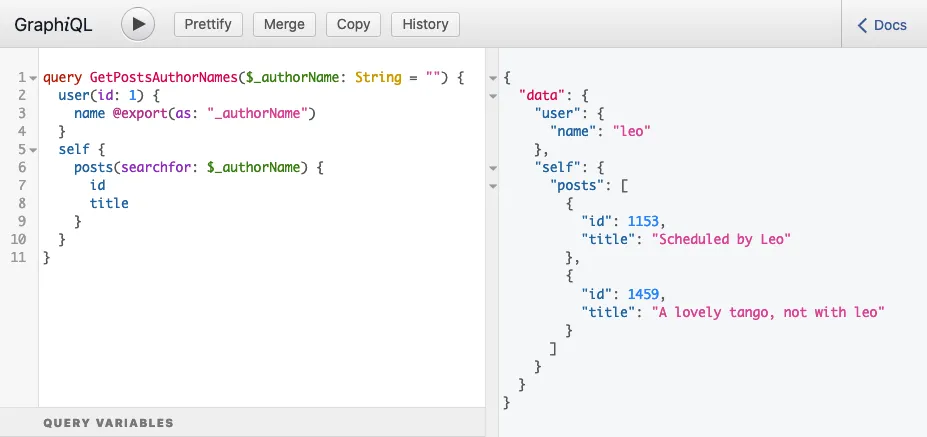
这就是为什么字段 posts(filter:{ search: $authorName }) 被放置在上述 Query 的 self 字段内,运行该 Query 会产生预期的响应:
query GetPostsAuthorNames {
user(by: {id: 1}) {
name @export(as: "authorName")
}
self {
posts(filter: { search: $authorName }) {
id
title
}
}
}
让我们探索此 Query 中类型的处理顺序,以理解为什么它能正常工作:
| # | 操作 | 列表 |
|---|---|---|
| 0 | 准备 FIFO 列表 | [Root] |
| 1a | 弹出列表中的第一个类型(Root) | [] |
| 1b | 处理从 Root 类型 Query 的所有字段:→ user(by: {id: 1})→ self将它们的类型( User 和 Root)添加到列表 | [User, Root] |
| 2a | 弹出列表中的第一个类型(User) | [Root] |
| 2b | 处理从 User 类型 Query 的字段:→ name @export(as: "authorName")由于它是标量类型( String),无需添加到列表 | [Root] |
| 3a | 弹出列表中的第一个类型(Root) | [] |
| 3b | 处理从 Root 类型 Query 的字段:→ posts(filter:{ search: $authorName })将其类型( Post)添加到列表 | [Post] |
| 4a | 弹出列表中的第一个类型(Post) | [] |
| 4b | 处理从 Post 类型 Query 的所有字段:→ id→ title由于它们是标量类型( ID 和 String),无需添加到列表 | [] |
| 5 | 列表为空,迭代结束。 |
现在我们可以看到问题已被解决:@export 在步骤 2b 执行,并在步骤 3b 被读取。
Multiple Query Execution 在解耦 Query 时正是这样做的:它转换 GraphQL 文档并添加 self 字段,使每个操作中的字段仅在所有先前操作的所有字段都已解析之后才执行。