
数据加载引擎
Gato GraphQL 使用服务端组件来表示数据模型(而非图或树)。让我们来看看它是如何执行数据加载流程以解析 GraphQL Query 的。
为了处理数据,我们必须将组件扁平化为类型(<FeaturedDirector> => Director、<Film> => Film、<Actor> => Actor),按其在组件层次结构中出现的顺序排列(Director,然后是 Film,再然后是 Actor),并以「迭代」方式逐一处理,在每次迭代中获取各类型的对象数据:

服务器的数据加载引擎必须实现以下(伪)算法来加载数据:
准备阶段:
- 准备一个空的队列,用于存储需要从数据库中获取的对象 ID 列表,按类型组织(每个条目格式为:
[类型 => ID 列表]) - 获取特色导演对象的 ID,并以类型
Director将其放入队列
循环直到队列中没有更多条目:
- 从队列中取出第一个条目:类型和 ID 列表(例如:
Director和[2]),并将此条目从队列中移除 - 使用该类型的
TypeDataLoader对象,对数据库执行单次 Query,获取该类型中具有这些 ID 的所有对象 - 如果该类型有关联字段(例如:类型
Director有类型Film的关联字段films),则从当前迭代中检索到的所有对象中收集这些字段的所有 ID(例如:所有Director类型对象的films字段中的所有 ID),并将这些 ID 以相应类型放入队列(例如:将 ID[3, 8]以类型Film放入队列)。
迭代结束时,我们将已加载所有类型的所有对象数据:
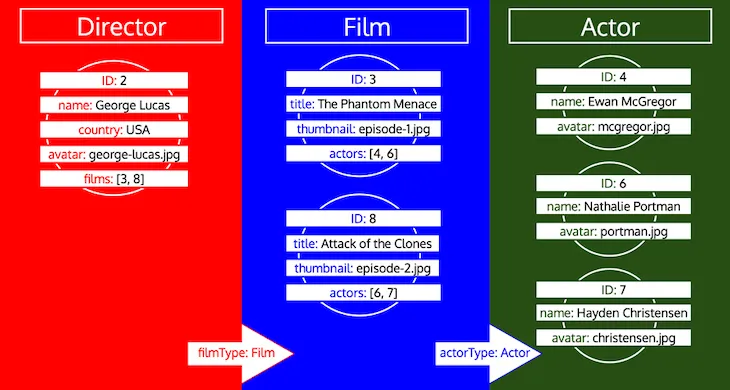
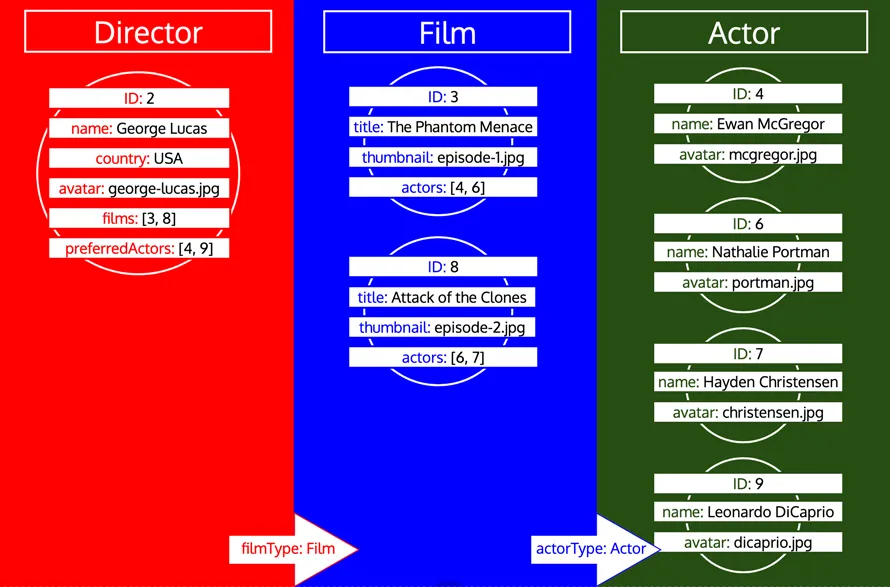
请注意,一个类型的所有 ID 会持续收集,直到该类型在队列中被处理为止。例如,如果我们向类型 Director 添加关联字段 preferredActors,这些 ID 将以类型 Actor 放入队列,并与类型 Film 的 actors 字段中的 ID 一起处理:
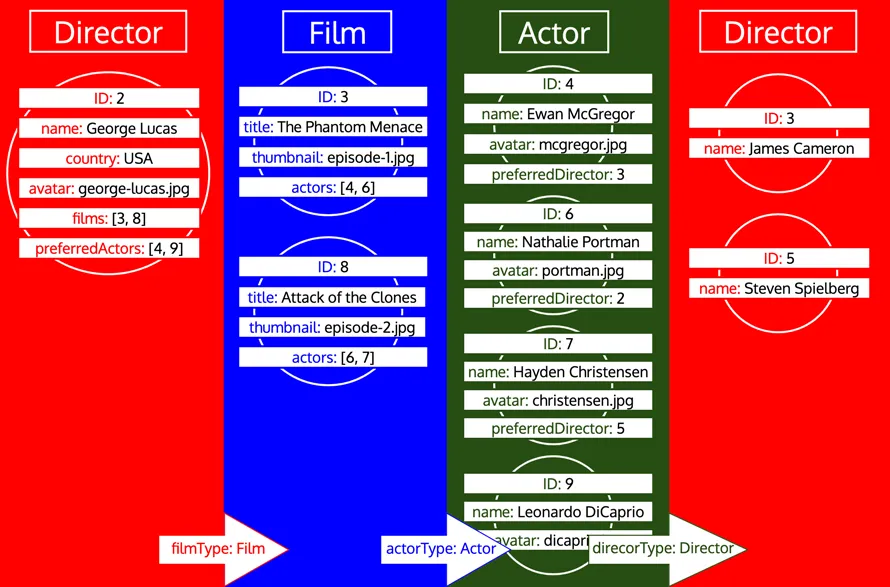
但是,如果某个类型已被处理,之后又需要从该类型加载更多数据,则会对该类型进行新一轮迭代。例如,向 Author 类型添加关联字段 preferredDirector,将使类型 Director 再次被加入队列:
现在我们已获取所有对象数据,需要将其整形为预期的响应结构,以反映 GraphQL Query 的形式。然而,如您所见,数据并不具备所需的树形结构。相反,关联字段包含的是嵌套对象的 ID,模拟了关系型数据库中的数据表示方式。因此,按照这种类比,每种类型所获取的数据可以用表格来表示,如下所示:
类型 Director 的表格:
| ID | name | country | avatar | films |
|---|---|---|---|---|
| 2 | George Lucas | USA | george-lucas.jpg | [3, 8] |
类型 Film 的表格:
| ID | title | thumbnail | actors |
|---|---|---|---|
| 3 | The Phantom Menace | episode-1.jpg | [4, 6] |
| 8 | Attack of the Clones | episode-2.jpg | [6, 7] |
类型 Actor 的表格:
| ID | name | avatar |
|---|---|---|
| 4 | Ewan McGregor | mcgregor.jpg |
| 6 | Nathalie Portman | portman.jpg |
| 7 | Hayden Christensen | christensen.jpg |
将所有数据以表格形式组织好,并了解各类型之间的关联关系(即 Director 通过字段 films 引用 Film,Film 通过字段 actors 引用 Actor),GraphQL 服务器便可轻松将数据转换为预期的树形结构:
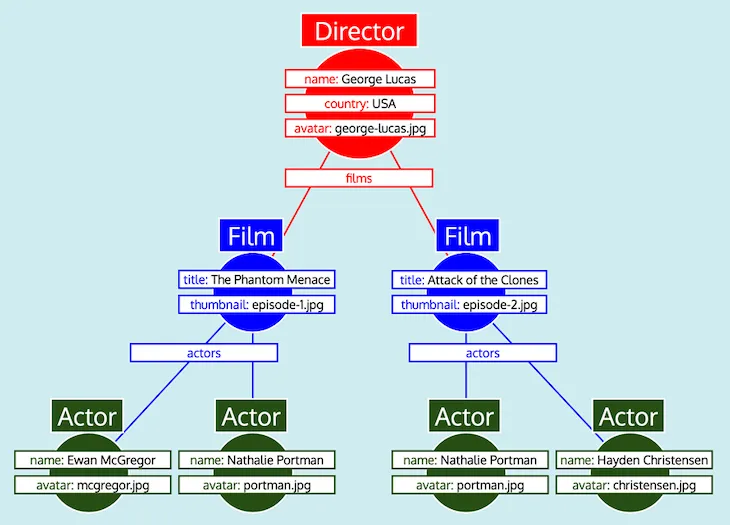
最终,GraphQL 服务器输出该树形结构,即预期响应的形式:
{
data: {
featuredDirector: {
name: "George Lucas",
country: "USA",
avatar: "george-lucas.jpg",
films: [
{
title: "Star Wars: Episode I",
thumbnail: "episode-1.jpg",
actors: [
{
name: "Ewan McGregor",
avatar: "mcgregor.jpg",
},
{
name: "Natalie Portman",
avatar: "portman.jpg",
}
]
},
{
title: "Star Wars: Episode II",
thumbnail: "episode-2.jpg",
actors: [
{
name: "Natalie Portman",
avatar: "portman.jpg",
},
{
name: "Hayden Christensen",
avatar: "christensen.jpg",
}
]
}
]
}
}
}分析方案的时间复杂度
让我们分析数据加载算法的大 O 表示法,以了解随着输入数量的增长,对数据库执行的 Query 数量如何增长,从而确认此方案具有良好的性能。
数据加载引擎按各类型对应的迭代加载数据。在开始某次迭代时,它已经拥有需要获取的所有对象的所有 ID 列表,因此可以执行单次 Query 来获取相应对象的所有数据。由此可得,对数据库的 Query 数量将随 Query 中涉及的类型数量线性增长。换言之,时间复杂度为 O(n),其中 n 是 Query 中的类型数量(但如果某个类型被迭代多次,则需在 n 中多次计入)。
此方案性能非常优越,远好于处理图时预期的指数级复杂度,以及处理树时预期的对数级复杂度。
已实现的 PHP 代码
数据加载流程发生在包 Component Model 中类 Engine 的函数 getComponentData 中。