
指令管道
指令被放置在管道中,按顺序执行。其初始设计很简单,如下所示:

在此架构中:
- 管道的输入是字段解析器提供的字段值
- 每个指令执行其逻辑,并将结果传递给管道中的下一个指令
- 管道的输出将是经过所有指令处理后的已解析字段值
然而,这个架构并没有充分发挥 GraphQL 的能力。以下是对实际指令管道所有阶段的描述,直至 Gato GraphQL 中实际实现的设计。
作为 Query 解析构建块的指令
最初,我们可以考虑让 GraphQL 服务器通过某种机制解析字段,然后将该值作为输入传递给指令管道。
然而,使用单一机制处理所有事情要简单得多:调用字段解析器(用于验证字段和解析字段)已经可以通过指令管道完成。在这种情况下,指令管道是解析 Query 的唯一机制。
因此,Gato GraphQL 服务器提供了两个特殊指令:
@validate调用字段解析器以验证字段是否可以被解析(例如:语法正确、字段存在等)- 如果验证成功,
@resolveValueAndMerge则调用字段解析器解析字段,并将值合并到响应对象中
这两个是特殊类型的「系统」指令:它们仅供 GraphQL 引擎使用,并在每个字段上隐式存在。(相比之下,标准指令是显式的:由用户添加到 Query 中。)
通过使用这两个指令,以下 Query:
query {
field1
field2 @directiveA
}...将被解析为:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge @directiveA
}管道现在如下所示(请注意,管道接收字段作为输入,而不是其初始解析值):

管道插槽
指令通常在 @resolveValueAndMerge 之后执行,因为它们大多涉及更新已解析字段的值。然而,也有一些指令必须在 @validate 之前执行,或在 @validate 和 @resolveValueAndMerge 之间执行。
例如:
- 为了测量解析字段所需的时间,指令
@traceExecutionTime可以通过在管道开头放置子指令@startTracingExecutionTime、在末尾放置@endTracingExecutionTime,来获取字段解析前后的当前时间 - 指令
@cache必须在执行@resolveValueAndMerge之前检查所请求的字段是否已被缓存,并在已缓存时直接返回该响应
管道将通过类 PipelinePositions 提供五个不同的插槽,指令将指定在哪个插槽中执行:
"beginning"插槽:最开始的位置"before-validate"插槽:在验证发生之前"middle"插槽:在验证之后、字段解析之前"after-resolve"插槽:在字段解析之后"end"插槽:最末尾的位置
指令管道现在如下所示(为简化起见,仅考虑 3 个阶段):

请注意,在此架构中,指令 @skip 和 @include 是如何轻松实现的:放置在 "middle" 插槽中,它们可以通过将标志 skipExecution 设置为 true,通知指令 @resolveValueAndMerge(以及管道中后续阶段的所有指令)不执行。
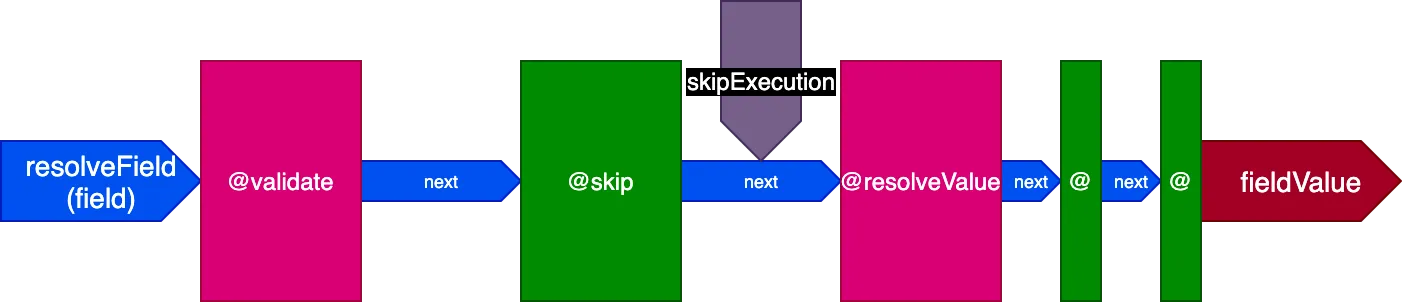
在单次调用中对多个字段执行指令
到目前为止,我们考虑的是将单个字段作为输入传递给指令管道。然而,在典型的 GraphQL Query 中,我们会接收多个字段来执行指令。
例如,在以下 Query 中,指令 @upperCase 在字段 "field1" 和 "field2" 上执行:
query {
field1 @upperCase
field2 @upperCase
field3
}此外,由于 GraphQL 引擎会将系统指令 @validate 和 @resolveValueAndMerge 添加到 Query 中的每个字段,因此以下 Query:
query {
field1
field2
field3
}...将被解析为以下 Query:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}因此,系统指令将始终接收所有字段作为输入。
由此,指令管道被设计为接收多个字段作为输入,而不是每次只接收一个:

这种架构更高效,因为对所有字段只执行一次指令比每个字段执行一次更快,并且会产生相同的结果。
例如,当验证用户是否已登录以授予对 schema 的访问权限时,该操作只需执行一次。运行以下代码:
if (isUserLoggedIn()) {
resolveFields([$field1, $field2, $field3]);
}比运行以下代码更高效:
if (isUserLoggedIn()) {
resolveField($field1);
}
if (isUserLoggedIn()) {
resolveField($field2);
}
if (isUserLoggedIn()) {
resolveField($field3);
}调用像 isUserLoggedIn 这样的本地函数时,差异可能不大,但在与外部服务交互时(例如通过 GraphQL 解析 REST 端点),差异会非常显著。在这些情况下,执行一次函数而不是多次,可能决定了是否能够提供某种功能。
让我们看一个例子。通过 @translate 指令与 Google Translate 交互时,GraphQL API 必须通过网络建立连接。执行以下代码将尽可能快:
googleTranslateFields([$field1, $field2, $field3]);相比之下,单独多次执行函数会产生更高的延迟,导致响应时间更长,降低 API 的性能。翻译 3 个字符串时(字段是要翻译的字符串)可能差别不大,但对于 100 个或更多字符串,肯定会产生影响:
googleTranslateField($field1);
googleTranslateField($field2);
googleTranslateField($field3);此外,将所有输入一次性传递给函数,可能比分别对每个字段执行函数产生更好的响应。再次以 Google Translate 为例,提供给服务的数据越多,翻译就越精确。
例如,执行以下代码时:
googleTranslate("fork");
googleTranslate("road");
googleTranslate("sign");在第一次独立执行时,Google 不知道 "fork" 的上下文,因此可能将其理解为餐具叉子、道路分叉或其他含义。然而,如果改为执行:
googleTranslate(["fork", "road", "sign"]);从这更广泛的信息量中,Google 可以推断出 "fork" 指的是道路的分叉,并返回精确的翻译。
正是由于这些原因,管道中的指令会一起接收所有输入字段,然后每个指令可以决定对这些输入执行逻辑的最佳方式(对每个输入单独执行一次、对所有输入合并执行一次,或介于两者之间的任何方式)。
管道现在如下所示:
为整个 Query 执行单一指令管道
刚才我们了解到,每个指令处理多个字段是有意义的,但这只在所有字段都应用了相同指令时才能很好地工作。当指令不同时,会导致更大的复杂性,使其实现变得困难,并会减少部分已获得的优势。
让我们看看这是如何发生的。考虑以下 Query:
query {
field1 @directiveA
field2
field3
}此指令等同于:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}在此场景中,字段 field2 和 field3 拥有相同的指令集,而 field1 拥有不同的指令集,因此我们需要生成 2 个不同的管道来解析该 Query:
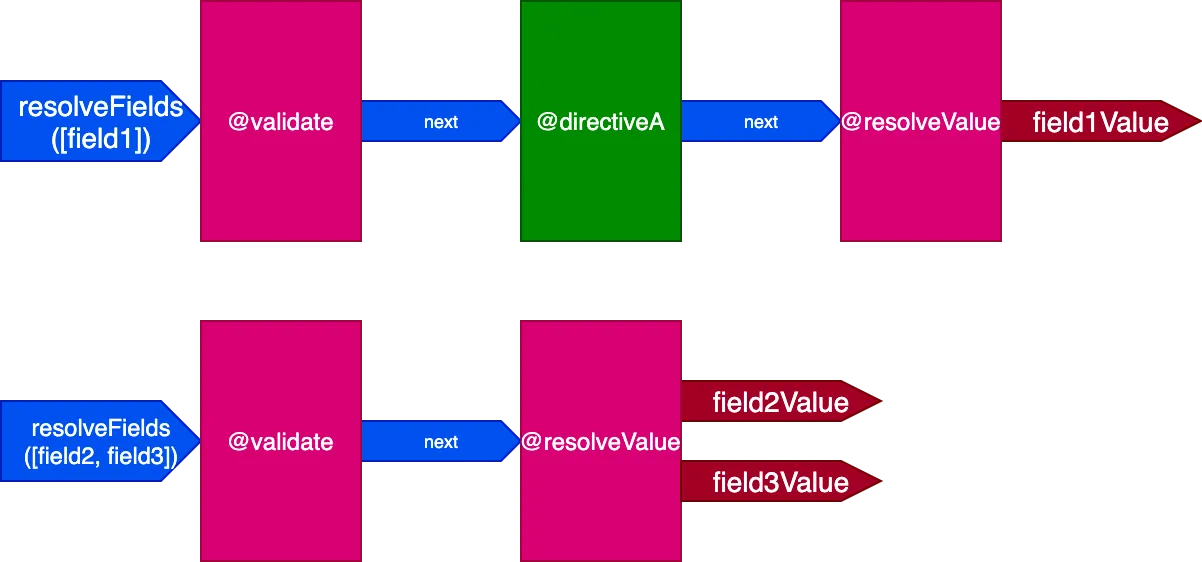
当所有字段都拥有唯一的指令集时,效果更为明显。考虑以下 Query:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}等同于:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge @directiveB @directiveC
field3 @validate @resolveValueAndMerge @directiveC
}在这种情况下,需要 3 个管道来处理 3 个字段:
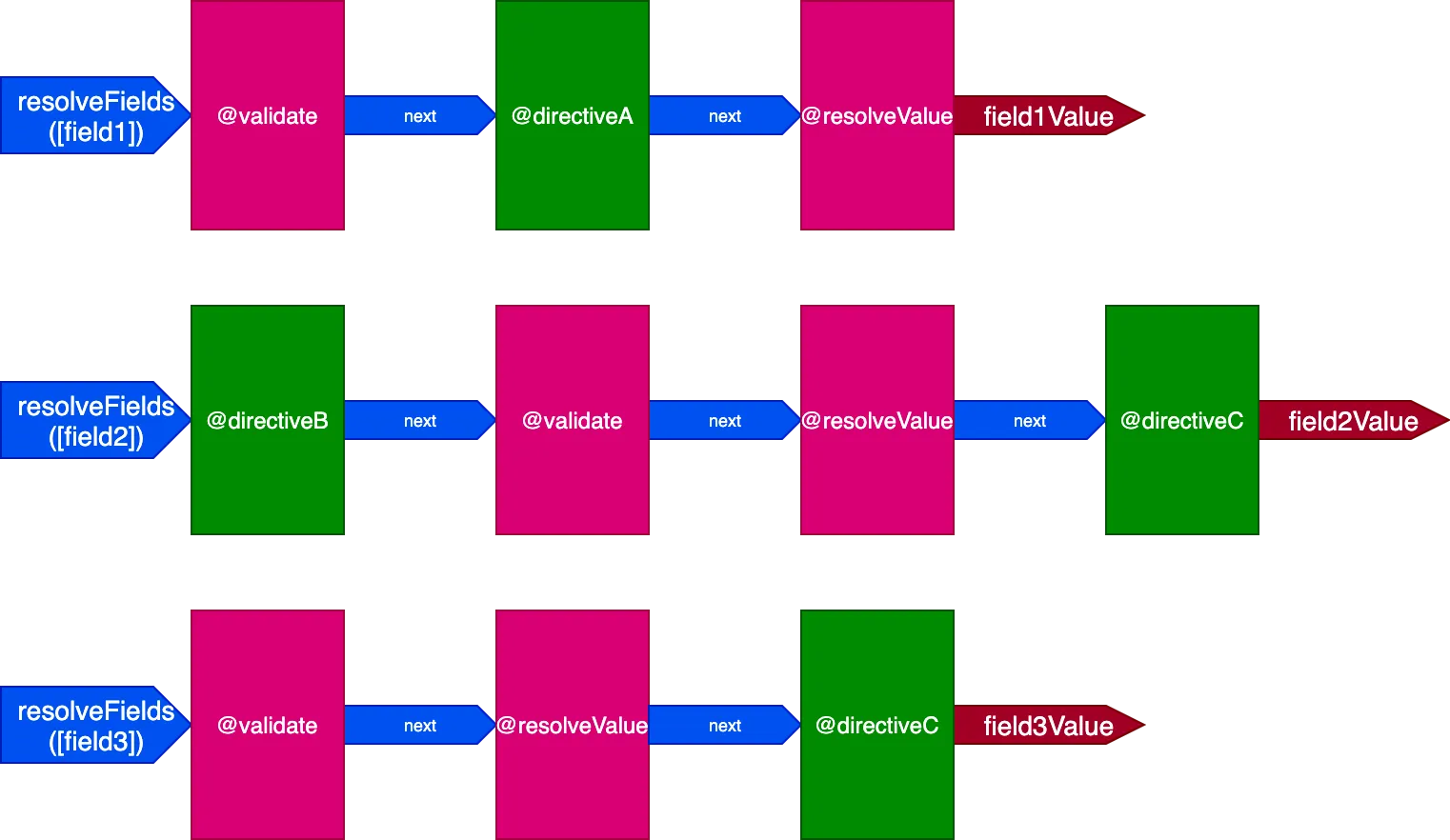
在这种情况下,尽管指令 @validate 和 @resolveValueAndMerge 应用于所有 3 个字段,但由于它们通过 3 个不同的指令管道执行,所以会相互独立地执行,这又回到了指令一次只对单个项目执行的状态。
解决此问题的方案是避免生成多个管道,而是用单一管道处理所有字段。因此,引擎不再将字段作为输入传递给管道,因为单一管道中并非所有指令都会与同一组字段交互;相反,每个指令必须接收其自己的字段列表作为其输入。
对于以下 Query:
query {
field1 @directiveA
field2
field3
}...指令 @validate 和 @resolveValueAndMerge 将接收所有 3 个字段作为输入,而 directiveA 只接收 "field1":
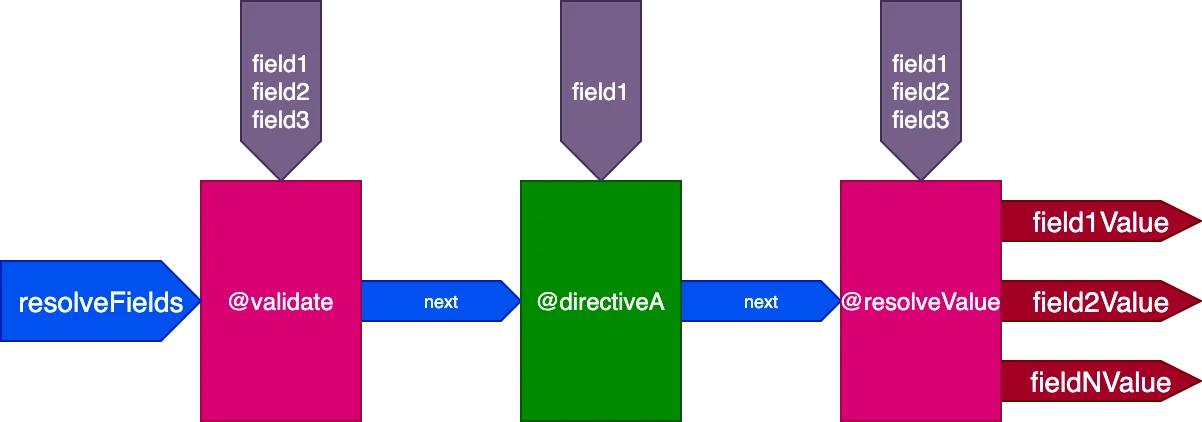
对于以下 Query:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}...指令 @validate 和 @resolveValueAndMerge 将接收所有 3 个字段作为输入,directiveA 只接收 "field1",directiveB 只接收 "field2",directiveC 接收 "field2" 和 "field3":
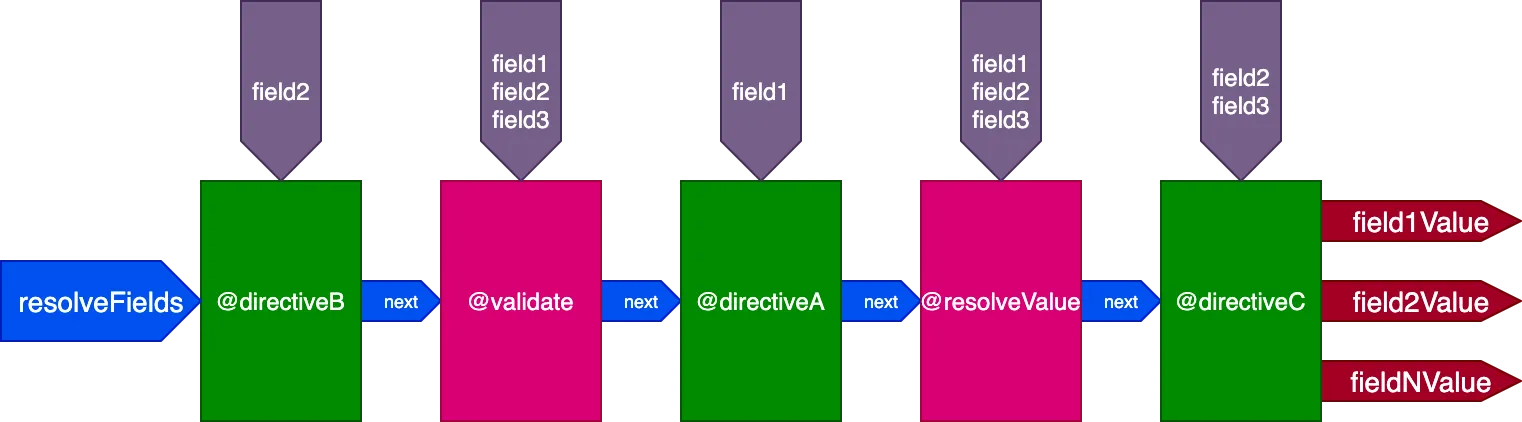
逐 ID 控制指令执行
到目前为止,某个阶段的指令可以通过标志 skipExecution 影响后续阶段指令的执行。然而,该标志对于所有情况的粒度不够细。
例如,考虑一个 @cache 指令,它被放置在 "end" 插槽中以存储字段值,这样下次查询该字段时,可以通过放置在 "middle" 插槽中的指令 @getCache 从缓存中检索其值:
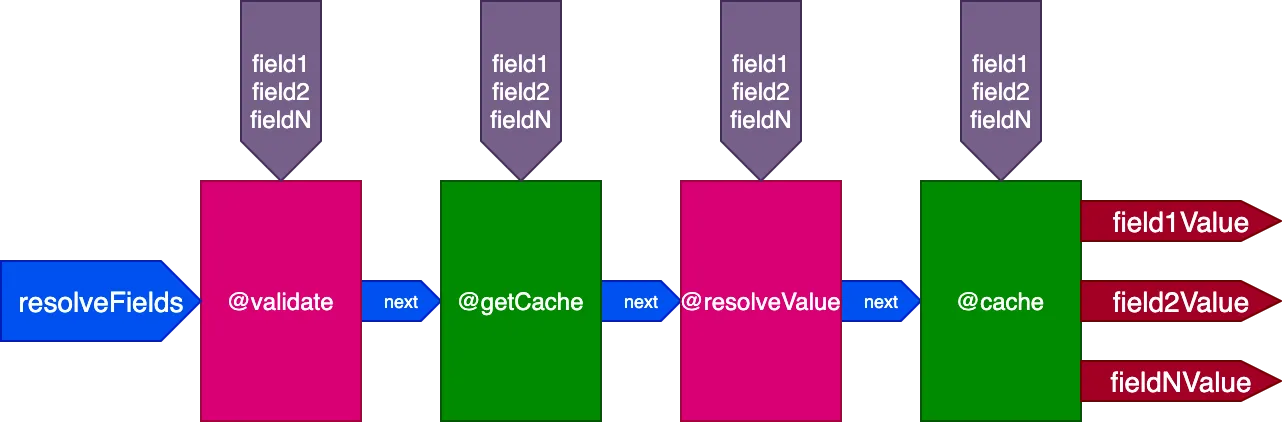
执行此 Query 时:
{
posts(pagination: { limit: 2 }) {
title @translate @cache
}
}服务器将检索并缓存 2 条记录。然后,我们执行相同的 Query,但应用于 4 条记录:
{
posts(pagination: { limit: 4 }) {
title @translate @cache
}
}执行第 2 次 Query 时,第 1 次 Query 的 2 条记录已被缓存,但其他 2 条记录尚未缓存。然而,要使用标志 skipExecution,需要所有 4 条记录都已被缓存。如果能从缓存中检索前 2 条记录,只解析另外 2 条记录,效果会更好。
因此,我们再次更新管道设计。废弃标志 skipExecution,改为通过输入对象 fieldIDs 向每个指令传递应用该指令的字段对应的对象 ID 列表:
{
field1: [ID11, ID12, ...],
field2: [ID21, ID22, ...],
...
fieldN: [IDN1, IDN2, ...],
}变量 fieldIDs 对每个指令是唯一的,每个指令都可以修改后续阶段所有指令的 fieldIDs 实例。这样,skipExecution 可以在逐 ID 的粒度上进行,只需从堆栈中所有后续指令的 fieldIDs 中删除该 ID 即可。
管道现在如下所示:
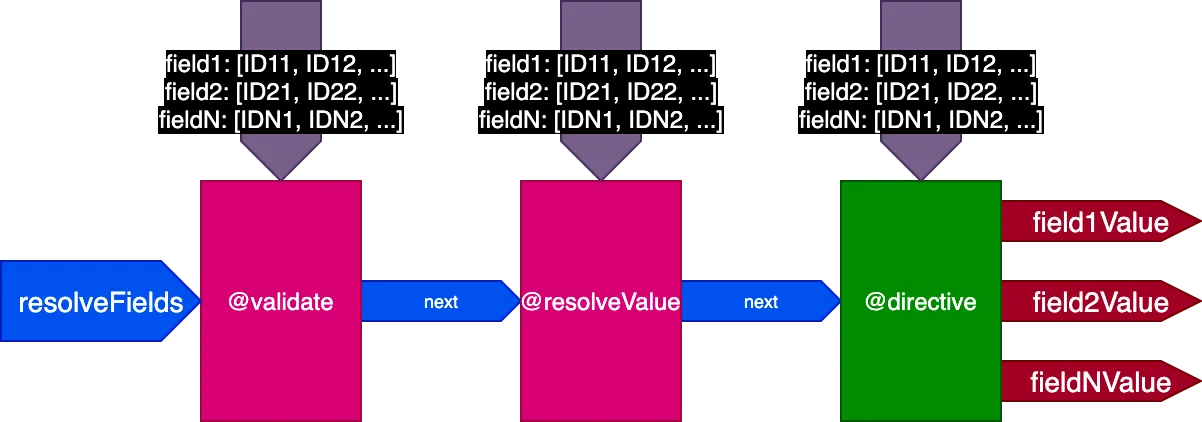
应用于前面的示例,执行翻译 2 条记录的第一个 Query 时,管道如下所示:
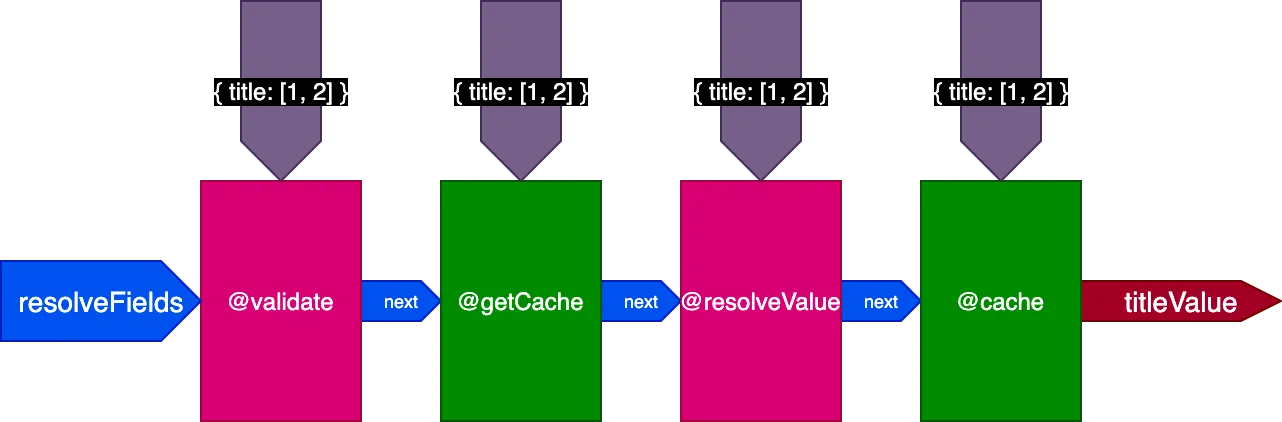
执行翻译 4 条记录的第二个 Query 时,指令 @getCache 获取所有 4 条记录的 ID,但 @resolveValueAndMerge 和 @cache 只接收最后 2 条记录(未被缓存)的 ID:
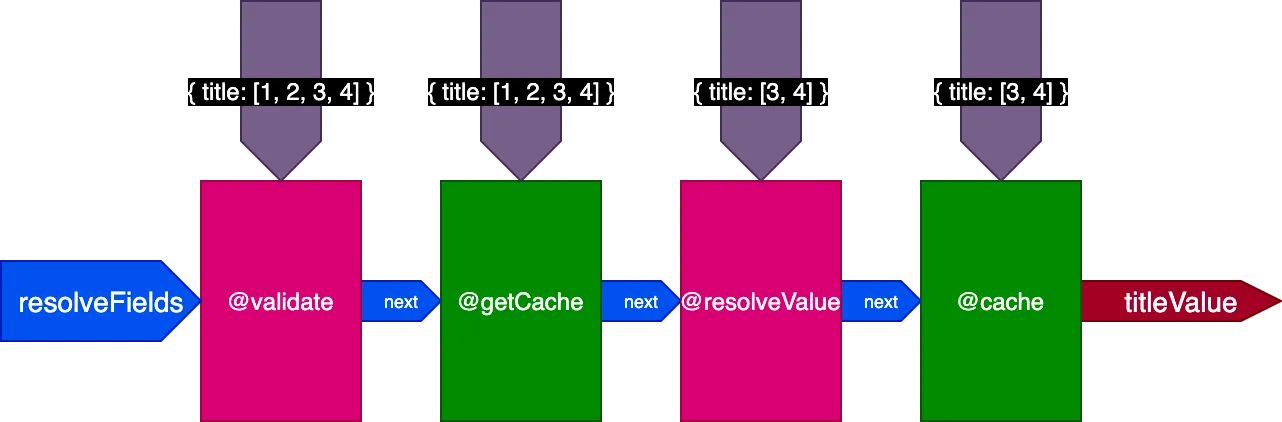
整合所有内容
这是指令管道的最终设计:
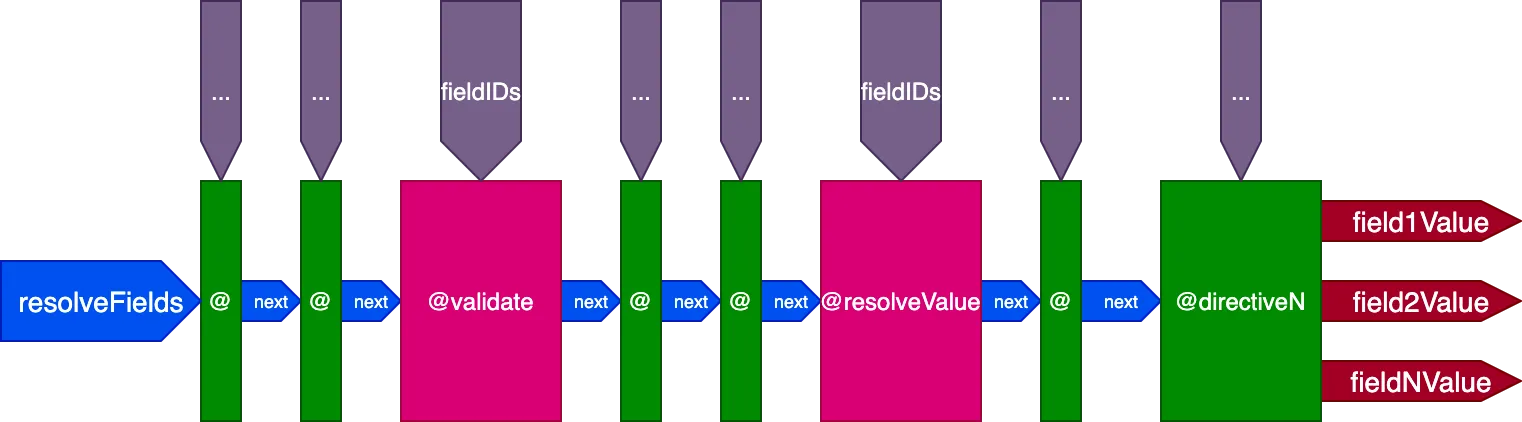
总结来说,其特点如下:
- 字段解析器通过指令
@validate和@resolveValueAndMerge从指令管道内部调用 - 指令可以放置在 5 个插槽的任意一个:
"beginning"、"before-validate"、"middle"、"after-validate"和"end" - 指令在单次调用中解析多个字段
- 单一管道包含 Query 中涉及的所有指令
- 每个指令通过变量
fieldIDs接收每个字段需要解析的自有 ID 集合 - 指令可以为管道中后续阶段的所有指令修改变量
fieldIDs